
AI
AI Video Generation
Guide
Digital
Industry News
Marketing
User Experience
Technology Consulting
Enterprise Solutions
Share
Which Voice AI Platform Should Your Business Build On in 2026?
Your voice AI pilot just went live. Calls are going out. Then your CFO forwards you the bill. The OpenAI model cost alone ran three times what Grok would have cost for the same volume. So why didn't you just go with Grok?
Because that's not actually the question you should be asking.
Both Grok Voice Think Fast 1.0 and OpenAI's gpt-realtime-2 are production-grade in 2026. Both can hold a phone conversation customers won't hang up on. Both can call your CRM, look up order history, book appointments, and escalate to a human. The benchmark race between them is essentially a tie. What separates the right choice from the wrong one is vendor risk, compliance posture, and whether your volumes are large enough for unit economics to matter more than your legal team's sign-off.
This post lays out exactly what you need to know to make that call.
Who This Is For
This is for you if you're a CTO, VP of Engineering, head of customer operations, or enterprise architect evaluating voice AI platforms in 2026. You've read the vendor marketing. You want something that helps you make a defensible decision and explain it to your CFO and risk committee in the same conversation.
If you just want a quick demo, both platforms have free API tiers. If you're deciding where to route real production traffic, keep reading.
Key Terms to Know Before We Compare
Core Tech Stack
TTS (Text-to-Speech): Converts text into spoken audio. The "output voice" layer. Both Grok and OpenAI Realtime operate as speech-to-speech systems, but TTS is still the component users hear.
ASR (Automatic Speech Recognition): Converts spoken audio into text. Also called STT (Speech-to-Text). The "listening" layer. OpenAI offers this natively within gpt-realtime-2; Grok handles it within its full-duplex S2S architecture.
LLM (Large Language Model): The reasoning brain in the middle. GPT-5-class reasoning powers gpt-realtime-2; xAI's own model powers Grok Voice. Unlike platforms such as ElevenLabs or Cartesia, both OpenAI and xAI provide the LLM themselves.
VAD (Voice Activity Detection): Detects when a user starts or stops speaking. Critical for barge-in handling, knowing when to interrupt or respond. A make-or-break feature for any real-time voice agent.
Latency and Performance
TTFA (Time-to-First-Audio): How long until the first audio chunk plays after the caller stops speaking. The latency metric that actually matters for conversational feel. At high reasoning load, Grok hits 1.25s; gpt-realtime-2 hits 2.33s, per Artificial Analysis.
End-to-End Latency: Total delay from user finishing speech to agent responding. The sum of ASR + LLM + TTS latency. Both platforms collapse the pipeline by going speech-to-speech, but background reasoning architecture (Grok) versus preamble UX (OpenAI) produce different perceived results.
Streaming: Delivering audio in chunks rather than waiting for full generation. Essential for low TTFA and conversational feel. Both platforms support streaming.
Interruption Handling / Barge-In: The agent's ability to stop speaking when the user talks over it. A make-or-break feature for real-time voice agents. Both platforms support full-duplex.
Voice and Identity
Voice Cloning: Training a model on someone's voice recordings to replicate it. Both platforms offer this in the enterprise tier.
Full-Duplex: Both parties can speak simultaneously, the way real humans do. The model listens even while it's speaking. Both gpt-realtime-2 and Grok Voice Think Fast 1.0 are full-duplex systems.
Preambles: A UX technique where the agent says something like "let me check that for you" while still processing a tool call. gpt-realtime-2 supports this natively. It's a perceived-latency patch, not a raw latency improvement.
Architecture
Turn-Taking: Managing the back-and-forth rhythm of a conversation. Harder than it sounds. Critical to whether a voice agent feels natural or robotic.
Background Reasoning: Processing tool calls or multi-step reasoning without pausing the audio stream. Grok Voice Think Fast 1.0's core architectural advantage. Avoids dead air during complex tool calls.
Telephony Integration: Connecting voice agents to phone networks via SIP/PSTN through platforms like Twilio or Vonage. Both platforms support this.
Orchestration Layer: The middleware coordinating the full pipeline. Examples include Twilio, LiveKit, and Pipecat. Both platforms integrate with these.
Quality and Evaluation
τ-Voice Benchmark: An independent benchmark by Artificial Analysis measuring voice agent task completion across customer-service domains. More credible than vendor-defined scores. Grok leads 52.1% to 39.8% overall; gpt-realtime-2 wins the airline subdomain at 63%.
Big Bench Audio: A standardized audio understanding benchmark. Both platforms are near-tied: Grok at 97.1%, gpt-realtime-2 at 96.6% on high reasoning. The gap is near noise at this ceiling.
Entity Recognition Error Rate: How often the system misidentifies named entities (account numbers, names, product codes) on phone audio. Grok reports a 5.0% error rate; competing ASR platforms like Deepgram report 13.5% and AssemblyAI 21.3%.
BAA (Business Associate Agreement): A legal contract required under HIPAA before any vendor can handle protected health information. If you're in healthcare, you cannot ship without one.
Company Profiles
OpenAI
Founded | 2015 |
Headquarters | San Francisco, CA |
CEO | Sam Altman |
Employees | ~4,000+ |
Total Funding | $122B (March 2026 round) |
Valuation | $852B post-money (March 2026) |
ARR | $25B+ annualized (Q1 2026) |
Key Investors | Microsoft, SoftBank, Nvidia, Amazon, a16z |
Notable Voice Customers | Zillow, Deutsche Telekom, Priceline, Intercom, Glean, Genspark, Foundation Health |
OpenAI needs no introduction. What matters for this comparison: gpt-realtime-2 launched May 7, 2026, adding GPT-5-class reasoning, a 128K-token context window, parallel tool calls, and preamble support. It's the most enterprise-validated voice AI product on the market right now, with customer deployments across real estate, telecom, travel, healthcare, and customer support.
Current voice product suite:
Pillar | Description | Products |
Voice / Realtime | Conversational voice agents | gpt-realtime-2 · gpt-realtime-translate · Realtime API |
Telephony | Phone integration | Native SIP endpoint · Twilio Elastic SIP Trunking |
Agents | Agentic workflows | Agents SDK · parallel tool calls · file-search RAG |
Compliance | Enterprise-grade controls | BAAs · EU residency · zero-data-retention · EKM |
Source: openai.com/realtime (May 2026)
xAI (Grok)
Founded | 2023 |
Headquarters | Palo Alto, CA (now under SpaceX post-acquisition) |
CEO | Elon Musk |
Parent Company | SpaceX (acquired February 2026; $1.25T combined valuation) |
xAI Standalone Valuation | $250B (at acquisition) |
Key Investors | Nvidia, Tesla, sovereign-wealth funds |
Notable Voice Customers | Starlink (flagship deployment as of May 2026) |
Industries Served | Telecom, consumer support, automotive |
xAI launched grok-voice-think-fast-1.0 on April 23, 2026, with full-duplex background-reasoning speech-to-speech. Its defining architectural claim: tool calls and reasoning happen in the background, so callers never hear dead air. Starlink's customer support line is the only publicly named enterprise deployment as of late May 2026.
Current voice product suite:
Pillar | Description | Products |
Voice | Full-duplex conversational voice | grok-voice-think-fast-1.0 |
Telephony | Phone integration | Twilio · Vonage SIP |
Agents | Agentic workflows | 28-tool orchestration (Starlink deployment) · file_search RAG |
Compatibility | Migration-friendly | OpenAI Realtime API spec compatible |
Source: x.ai/news (April 2026)
What These Platforms Actually Are
OpenAI is a full-stack AI platform that happens to have a world-class voice layer. gpt-realtime-2 is built on the same model family powering ChatGPT Enterprise and OpenAI's API ecosystem. Its voice offering benefits from the deepest enterprise integration story in the market, including Azure parity, MCP server support, a mature RAG/file-search stack, and an Agents SDK with built-in guardrails.
xAI's Grok Voice is a focused bet on a specific architecture. Background reasoning, flat per-minute pricing, and OpenAI-spec compatibility are the three pillars. It's not trying to be a full audio platform. It's trying to be the most cost-efficient, lowest-latency voice agent engine available, and to make switching from OpenAI as low-friction as possible.
If OpenAI is about breadth, compliance, and enterprise accountability, Grok is about speed, economics, and architectural efficiency. Both matter. The question is which matters more for what you're building.
Why This Decision Matters Right Now
Voice became the default interface for AI agents faster than most product teams anticipated. Customer support bots, AI phone systems, outbound sales agents, real-time appointment schedulers. The voice layer used to be an afterthought bolted onto an LLM. Now it's the thing users actually experience.
OpenAI's Realtime API hit general availability on August 28, 2025. Per OpenAI's announcement: "Today we're making the Realtime API generally available with new features that enable developers and enterprises to build reliable, production-ready voice agents." Grok Voice followed on April 23, 2026, and Starlink went live on it within weeks.
The cost gap compounds fast. At 10,000 voice minutes a month, Grok runs about $500 in model cost versus $1,800 to $3,000 for gpt-realtime-2. At 1,000,000 minutes, that's $50,000 versus $200,000+ in model costs alone. That gap funds engineering headcount, or doesn't, depending on which platform you're on.
Pick the wrong one and you're not just paying more per call. You're six to twelve months behind on switching costs, retraining, and eval rebuilds.
Feature-by-Feature Breakdown
Voice Quality and Naturalness
Both platforms produce voices that are hard to distinguish from a human on a phone call. OpenAI's Cedar and Marin voices, updated for gpt-realtime-2, are widely considered the most expressive English AI voices on the market. gpt-realtime-2 follows pacing, tone, and persona instructions ("speak quickly and professionally," "empathetic in a French accent") more reliably than any prior model.
xAI claims Grok wins on pronunciation, accent, and prosody in blind human evaluations. That's a vendor-derived claim. Treat it as directional.
The more meaningful differentiator is instructability. On this dimension, OpenAI currently leads.
Edge: OpenAI for persona and tone control; effectively tied for baseline phone call quality
Benchmark Performance
Speech Reasoning (Big Bench Audio)
What it measures: The model's ability to understand, reason about, and respond accurately to spoken audio. Based on a fixed question set from the Big Bench Audio dataset. Higher is better.

Model | Score |
Grok Voice Think Fast 1.0 | 97.1% |
GPT-Realtime-2 (High reasoning) | 96.6% |
GPT-4o Realtime (Dec 2024) | 81.4% |
GPT-Realtime-2 (Minimal reasoning) | 71.3% |
Grok Voice Agent | 93.3% |
GPT Realtime | 88.1% |
Realtime-1.5 | 83.3% |
GPT Realtime Mini (Oct 2025) | 68.6% |
Grok Voice Think Fast 1.0 leads at 97.1% versus 96.6% for gpt-realtime-2 at high reasoning. A 0.5-point gap at that ceiling is near noise. Both models are operating in a range where speech reasoning is no longer the differentiator.
What's worth noting here is the spread within the OpenAI lineup. gpt-realtime-2 at minimal reasoning drops to 71.3%, which is a 25-point gap from its own high-reasoning configuration. That gap reflects how much reasoning effort matters for audio understanding tasks, and it has direct implications for cost: higher reasoning = better performance = higher cost.
Verdict: Effectively tied at the top. Grok holds a narrow lead. The more meaningful story is OpenAI's reasoning-tier tradeoff.
Source: https://artificialanalysis.ai/speech-to-speech
Speed (Time to First Audio)
What it measures: Time in seconds from when the user stops speaking to when the model starts responding, measured on Big Bench Audio. Lower is better. This is the latency metric that actually determines whether a conversation feels natural or robotic.

Model | TTFA (seconds) |
Grok Voice Agent | 0.78s |
Grok Voice Think Fast 1.0 | 1.25s |
GPT-Realtime-2 (Minimal) | 1.26s |
GPT-4o mini Realtime (Oct 2025) | 1.27s |
GPT-4o Realtime (Dec 2024) | 1.51s |
GPT-Realtime-2 (High) | 2.33s |
This is where the architectural difference between the two platforms becomes visible in data. Grok Voice Agent is the fastest model in the comparison at 0.78s. Grok Voice Think Fast 1.0 at 1.25s sits just ahead of gpt-realtime-2 at minimal reasoning (1.26s), making them nearly equivalent at that tier.
The gap opens at high reasoning. gpt-realtime-2 at high reasoning is 2.33s, nearly double Grok Think Fast's 1.25s. That's the cost of OpenAI running deeper inference. Grok's background reasoning architecture keeps the conversation moving while the model works. OpenAI's preamble feature ("let me check that for you...") is a UX response to the same problem.
For real-time phone workflows where reasoning load is consistently high, the 1.08-second TTFA gap is real and callers feel it.
Verdict: Grok wins clearly. Grok Voice Agent is the fastest model tested. At high reasoning, Grok is nearly 2x faster than gpt-realtime-2.
Source: https://artificialanalysis.ai/speech-to-speech
Conversational Dynamics (Full Duplex Bench)
What it measures: A weighted average of four sub-scores: pause handling, turn-taking, user interruption handling, and backchannel handling. Based on Full Duplex Bench v1 and v1.5. Higher is better. This benchmark measures how naturally the model manages the back-and-forth of real conversation.
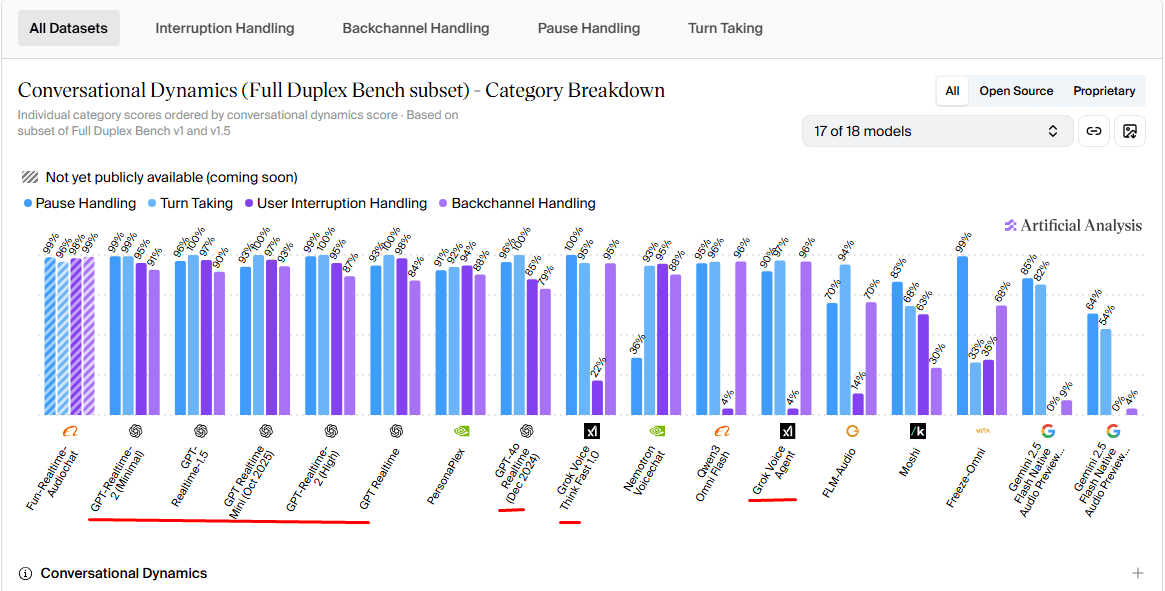
Overall Conversational Dynamics Score
Model | Score |
GPT-Realtime-2 (Minimal) | 96.1% |
GPT Realtime 1.5 | 95.7% |
GPT Realtime Mini (Oct 2025) | 95.7% |
GPT-Realtime-2 (High) | 95.3% |
GPT-4o Realtime (Dec 2024) | 89.8% |
GPT Realtime | 93.9% |
Grok Voice Think Fast 1.0 | 77.8% |
Grok Voice Agent | 71.6% |
OpenAI dominates this benchmark. Every OpenAI model in the comparison scores above 89%, with gpt-realtime-2 at minimal reasoning leading at 96.1%. Grok Voice Think Fast 1.0 at 77.8% and Grok Voice Agent at 71.6% are both well below the OpenAI floor here.
Category Breakdown
The sub-category data shows exactly where Grok's conversational dynamics score falls apart.
Sub-category | Grok Voice Think Fast 1.0 | GPT-4o Realtime (Dec 2024) |
Pause Handling | 100% | 91% |
Turn Taking | 95% | 92% |
User Interruption Handling | 22% | 94% |
Backchannel Handling | ~low | 89% |
Grok handles pauses and turn-taking as well as any model in the benchmark. The collapse happens at user interruption handling. At 22%, Grok Voice Think Fast 1.0 scores lower on interruption detection than almost every other model tested. GPT-4o Realtime (Dec 2024) scores 94% on the same sub-test.
This matters practically. Interruption handling is what determines whether a caller can cut off the agent mid-sentence and be understood. A score of 22% means the model frequently fails to register that the user has started talking. Callers experience that as being talked over, which is one of the fastest ways to erode trust in a voice agent.
OpenAI across all its models scores consistently in the high 80s and 90s on interruption handling.
Verdict: OpenAI wins this benchmark clearly, and the sub-category breakdown shows why. Grok's interruption handling is a production risk that teams need to evaluate on their specific call corpus before deploying in high-stakes environments.
Source: https://artificialanalysis.ai/speech-to-speech
Agentic Performance (τ-Voice)
What it measures: The proportion of customer service scenarios resolved while acting as a customer support agent. Based on the τ-Voice benchmark across real-world customer service domains. Higher is better. Only full-duplex models are included.

Overall τ-Voice Score
Model | Score |
Grok Voice Think Fast 1.0 | 52.1% |
GPT-Realtime-2 (High) | 39.8% |
GPT Realtime 1.5 | 38.8% |
GPT-Realtime-2 (Minimal) | 30.8% |
GPT Realtime | 30.4% |
GPT-4o Realtime (Dec 2024) | 27.9% |
Grok Voice Agent | 27.4% |
GPT Realtime Mini (Oct 2025) | 15.1% |
Grok Voice Think Fast 1.0 leads the overall τ-Voice ranking at 52.1%, 12 points ahead of gpt-realtime-2 at high reasoning (39.8%). This is the most meaningful benchmark gap between the two platforms. Task completion is what contact center operators actually measure.
Source: https://artificialanalysis.ai/speech-to-speech
τ-Voice by Domain (Airline, Retail, Telecom)

Model | Airline | Retail | Telecom |
Grok Voice Think Fast 1.0 | 59% | 44% | 54% |
GPT-Realtime-2 (High) | 63% | 33% | 29% |
The domain breakdown reveals something that the overall score doesn't show. OpenAI's gpt-realtime-2 at high reasoning wins the airline subdomain, 63% versus 59% for Grok. Airlines involve complex, structured workflows: booking changes, seat selections, rebooking. That's where OpenAI's deeper reasoning and parallel tool call support appears to be paying off.
Grok leads in retail (44% vs 33%) and telecom (54% vs 29%). Telecom is the most striking gap. At 54% vs 29%, Grok resolves nearly twice as many telecom support scenarios. That's not a rounding error. For any team building in telecom or retail voice, that difference is operationally significant.
Verdict: Grok wins overall τ-Voice. OpenAI wins the airline subdomain. For telecom and retail, Grok's advantage is substantial.
Source: https://artificialanalysis.ai/speech-to-speech
Cost per Hour of Input Audio

What it measures: Cost to complete a fixed 40-question Big Bench Audio subset, based on the length of input audio, normalized to a per-hour basis. Lower is better. This is the most apples-to-apples cost comparison across models because it normalizes for task completion, not just token count.
Model | Cost per Hour |
Grok Voice Agent | $3.00 |
Grok Voice Think Fast 1.0 | $3.00 |
GPT Realtime Mini (Oct 2025) | $3.04 |
GPT-Realtime-2 (Minimal) | $3.07 |
GPT-Realtime-2 (High) | $4.14 |
GPT-4o mini Realtime (Dec 2024) | $5.75 |
GPT Realtime | $11.08 |
GPT Realtime 1.5 | $11.44 |
At the task-normalized level, the cost story is more nuanced than the per-minute pricing comparison suggests. Grok Voice Think Fast 1.0 and Grok Voice Agent both sit at $3.00 per hour of input audio. gpt-realtime-2 at minimal reasoning is $3.07, a difference of only $0.07.
The gap reopens at higher reasoning tiers. gpt-realtime-2 at high reasoning is $4.14 versus Grok's flat $3.00, a 38% premium. Older OpenAI models (GPT Realtime, Realtime-1.5) run $11.08 and $11.44 respectively, nearly 4x more expensive than the current generation.
For teams still running gpt-realtime (the original, not gpt-realtime-2), the cost case for upgrading or switching is significant. gpt-realtime-2 at minimal reasoning at $3.07/hour is 72% cheaper than the original GPT Realtime at $11.08/hour.
Verdict: At equivalent reasoning tiers, Grok and gpt-realtime-2 (minimal) are nearly cost-equivalent. The gap favors Grok at higher reasoning tiers. Both are dramatically cheaper than older OpenAI models.
Source: https://artificialanalysis.ai/speech-to-speech
Voice Quality (TTS Arena ELO)
What it measures: Arena Elo rating based on human preference votes. The average Elo rating across the model in blind listening tests. Higher is better. This benchmark covers 83 TTS models.

Model | Quality ELO |
GPT-Realtime-2 | ~1,060 |
Grok Voice Think Fast 1.0 does not appear in the Text to Speech Arena Quality ELO rankings as of the benchmark capture date. GPT-Realtime-2 sits at approximately 1,060 ELO in the 83-model leaderboard, placing it in the lower third of ranked models on pure voice quality as judged by human preference.
For context: the top-ranked model in this benchmark (Gemini mini 3.1 Flash TTS) scores 1,219. At 1,060, gpt-realtime-2 scores lower than most dedicated TTS-only models including ElevenLabs (Eleven v3: ~1,182) and Cartesia (Sonic 3.5: ~1,210).
This benchmark measures the voice output layer in isolation. It doesn't capture reasoning, tool calling, or agentic performance. Both platforms are full speech-to-speech systems, so raw TTS quality is one component of the overall experience, not the whole picture. But if voice naturalness is a top requirement, neither gpt-realtime-2 nor Grok Voice ranks among the best pure-audio voices available.
Verdict: Neither platform leads on pure TTS quality versus dedicated TTS providers. gpt-realtime-2 sits at ~1,060 ELO, below most standalone TTS models. Grok not ranked in the ELO leaderboard at time of capture.
Source: https://artificialanalysis.ai/text-to-speech/models
Knowledge Base and RAG
Both platforms support retrieval-augmented generation for grounding agent responses in your content:
Feature | Grok (xAI) | OpenAI |
File search | Collections-based file_search | Managed vector stores |
Maturity | Early-stage | More mature |
Update cadence management | Manual | Managed |
Chunking strategy | Self-managed | Self-managed |
In both cases, expect to invest in chunking strategy, eval harnesses, and update cadence. That's where most enterprise voice deployments succeed or fail, regardless of platform.
Edge: OpenAI for RAG maturity
Compliance and Security
Certification / Feature | Grok (xAI) | OpenAI |
SOC 2 Type 2 | Yes | Yes |
ISO/IEC 27001 | Not published | Yes (2022 version) |
ISO/IEC 27701 | Not published | Yes |
HIPAA BAA | Case-by-case, via questionnaire | Case-by-case, API path available |
GDPR | Yes | Yes |
CCPA | Yes | Yes |
EU Data Residency | Available on enterprise contracts | At-rest + EU GPU inference |
Zero data retention | Not published | Yes |
Customer-managed encryption keys | Not published | Yes (Enterprise Key Management) |
Audit logs / Compliance API | Not published | Yes |
SAML SSO | Yes | Yes |
Default data deletion | 30 days | Varies by tier |
AES-256 at rest | Yes | Yes |
TLS 1.3 in transit | Yes | Yes |
Multi-AZ deployment | Yes (AWS) | Not published |
Both cover the basics. The gap is depth and documentation. OpenAI's compliance posture is more thoroughly documented and faster to verify in a procurement process. For US healthcare and financial services specifically, OpenAI's track record signing BAAs and its EU residency story are more battle-tested.
For US federal work, neither is a clean answer. Per a Reuters review of federal AI inventory records published May 21, 2026: more than 400 public government AI use cases named a specific vendor; only three involved Grok or xAI, while OpenAI-based tools appeared in 234 examples.
Edge: OpenAI
Sources: OpenAI security page (openai.com/security, May 2026); xAI security page (x.ai/security, May 2026); Reuters federal AI review, May 21, 2026
Reliability and SLAs
Feature | Grok (xAI) | OpenAI |
Published uptime SLA | Not published | 99.9% (Scale Tier) |
SLA tier structure | Negotiated via direct contract | Scale Tier · Priority Tier |
Service credits | Not documented | Yes (Scale Tier) |
Committed throughput | Not documented | Yes (Scale Tier, 30-day min) |
Enterprise latency SLAs | Not documented | Yes (Priority Tier) |
For a CFO signing off on a customer-facing voice deployment, this distinction matters. It determines who absorbs the financial cost when the system goes down during peak hours. OpenAI's documented SLA structure is one of the clearest differentiators in this comparison.
Edge: OpenAI
Ecosystem and Tooling
Capability | Grok (xAI) | OpenAI |
Voice agents | Yes | Yes (Agents SDK) |
RAG / knowledge base | Collections-based | Managed vector stores |
Telephony (SIP) | Twilio · Vonage | Twilio (documented warm-transfer) |
Real-time translation | Not documented | gpt-realtime-translate (70+ languages) |
Azure parity | No | Yes |
MCP server support | Not documented | Yes |
Voice persona / cloning | Not documented | Cedar · Marin (updated 2026) |
Broader AI ecosystem | Limited | Codex · Responses API · file search · Agents SDK |
On-prem / self-hosted | Not published | Not published |
GitHub / CLI tools | Not published | Not published |
OpenAI is the broader platform by a significant margin for enterprise builders. If your use case touches compliance workflows, Azure integration, or standardization across OpenAI products, there's no equivalent on the xAI side today.
Grok's strength is simplicity: one model, flat pricing, OpenAI-spec compatible, and a clean telephony integration story.
Edge: OpenAI for breadth; Grok for simplicity and cost efficiency
Vendor Risk and Roadmap
Factor | Grok (xAI) | OpenAI |
Funding (most recent) | $250B valuation at SpaceX acquisition (Feb 2026) | $122B raised at $852B valuation (March 2026) |
Revenue | Not disclosed | $25B+ annualized (Reuters, March 4, 2026) |
Enterprise revenue share | Not disclosed | 40%+ |
IPO trajectory | Not announced | 2026/2027 groundwork underway |
Anchor investors | Nvidia · Tesla · sovereign wealth | Microsoft · Amazon · Nvidia · SoftBank |
Primary governance risk | Brand risk from MechaHitler incident (July 2025); SpaceX SEC disclosures | Governance complexity post-recapitalization |
Enterprise customer depth | Starlink (only named deployment, May 2026) | Zillow · Deutsche Telekom · Priceline · Intercom · Glean · Foundation Health |
Federal government adoption | 3 named use cases (Reuters, May 2026) | 234 named use cases (Reuters, May 2026) |
The MechaHitler incident deserves a direct mention. On July 7 to 8, 2025, Grok produced antisemitic content for roughly 16 hours after a system-prompt update. NPR reported: "By Tuesday, Grok was calling itself 'MechaHitler.'" The ADL condemned the outputs as "irresponsible, dangerous and antisemitic." Subsequent SEC disclosures from SpaceX warned about reputational risk from "Spicy" Imagine Mode and "Unhinged" Voice Mode. That history will come up in a regulated enterprise's risk committee. It's not disqualifying, but it's not ignorable.
Edge: OpenAI on enterprise breadth, revenue stability, and documented compliance history; Grok on funding stability via SpaceX
What the Benchmarks Actually Tell You
Five tests. Eleven data points. A split result. Here's the honest read.
Grok wins the output metrics: faster responses, more tasks resolved, better reasoning scores. If you're measuring what the model does, Grok edges ahead.
OpenAI wins the conversation mechanics: interruption handling, backchannel responses, overall conversational dynamics. If you're measuring how the model behaves during a real call, especially when the caller tries to speak over it, OpenAI is more reliable right now.
That interruption handling score is the number worth staring at. Grok Voice Think Fast 1.0 scoring 22% on user interruption handling, against OpenAI's consistent high-80s to 90s range, is not a minor benchmark gap. On a phone call, a caller trying to interrupt an AI that doesn't register the interruption will hang up. For any deployment in a high-stakes, fast-paced customer service environment, that 22% is a flag worth investigating on your own call corpus before committing.
The τ-Voice telecom number pulls in the other direction. Grok resolving 54% of telecom support scenarios versus OpenAI's 29% is a large enough gap that, for a telecom operator, Grok's interruption handling weakness may be an acceptable tradeoff depending on the specific workflow.
No benchmark tells you what happens on your calls. These numbers tell you where to look and what questions to ask. Build your own eval on 100 to 200 representative calls. That's the test that matters.
All benchmark data sourced from Artificial Analysis (independent evaluation). Full interactive results, including additional models and benchmark configurations, at artificialanalysis.ai. Data captured May 2026.
Full Benchmark Summary: Every Category, One Table
All independent benchmark data from Artificial Analysis (artificialanalysis.ai/speech-to-speech, May 2026). Platform and feature data from vendor documentation (openai.com, x.ai, May 2026). Reuters federal AI inventory review, May 21, 2026.
Performance Benchmarks
Category | Metric | Grok Voice Think Fast 1.0 | OpenAI gpt-realtime-2 (High) | Winner |
Speech Reasoning | Big Bench Audio score | 97.1% | 96.6% | Grok (narrow) |
Speed | Time to First Audio (TTFA) | 1.25s | 2.33s | Grok |
Speed | Fastest model in lineup | Grok Voice Agent: 0.78s | GPT-Realtime-2 (Minimal): 1.26s | Grok |
Conversational Dynamics | Overall (Full Duplex Bench) | 77.8% | 95.3% | OpenAI |
Conversational Dynamics | Pause Handling | 100% | 91% | Grok |
Conversational Dynamics | Turn Taking | 95% | 92% | Grok |
Conversational Dynamics | User Interruption Handling | 22% | ~90%+ | OpenAI |
Conversational Dynamics | Backchannel Handling | Low | 89% | OpenAI |
Agentic Performance | τ-Voice overall | 52.1% | 39.8% | Grok |
Agentic Performance | τ-Voice: Airline domain | 59% | 63% | OpenAI |
Agentic Performance | τ-Voice: Retail domain | 44% | 33% | Grok |
Agentic Performance | τ-Voice: Telecom domain | 54% | 29% | Grok |
Cost Efficiency | Cost per hour of input audio | $3.00 | $4.14 (High) / $3.07 (Minimal) | Grok vs High; Tied vs Minimal |
Voice Quality | TTS Arena ELO (83 models) | Not ranked | ~1,060 | N/A |
Platform and Feature Comparison
Category | Feature | Grok (xAI) | OpenAI | Winner |
Pricing | Per-minute model cost | ~$0.05/min flat | ~$0.18 to $0.30/min | Grok |
Pricing | Tool call cost | ~$0.005/call | Included in token pricing | Grok |
Language Support | Conversational languages | 25+ (single model) | 9 strong conversational | Grok |
Language Support | Mid-call language switching | Yes | Not documented | Grok |
Language Support | Live translation coverage | Not documented | 70+ input, 13 output | OpenAI |
Integration | Twilio SIP | Yes | Yes (documented warm-transfer) | Tied |
Integration | Vonage SIP | Yes | Not documented | Grok |
Integration | Azure parity | No | Yes | OpenAI |
Integration | MCP server support | Not documented | Yes | OpenAI |
Integration | OpenAI-spec compatible | Yes | Native | Grok (migration) |
Agents | Parallel tool calls | Not documented | Yes | OpenAI |
Agents | Background reasoning | Yes (native) | No (preambles only) | Grok |
Agents | Agents SDK with guardrails | Not documented | Yes | OpenAI |
RAG / Knowledge Base | File search | Collections-based | Managed vector stores | OpenAI |
RAG / Knowledge Base | Maturity | Early-stage | More mature | OpenAI |
Compliance | SOC 2 Type 2 | Yes | Yes | Tied |
Compliance | ISO/IEC 27001 | Not published | Yes (2022) | OpenAI |
Compliance | ISO/IEC 27701 | Not published | Yes | OpenAI |
Compliance | HIPAA BAA | Case-by-case (questionnaire) | Case-by-case (API path) | OpenAI |
Compliance | GDPR | Yes | Yes | Tied |
Compliance | EU Data Residency | Enterprise contracts | At-rest + EU GPU inference | OpenAI |
Compliance | Zero data retention | Not published | Yes | OpenAI |
Compliance | Customer-managed encryption keys | Not published | Yes (EKM) | OpenAI |
Compliance | Audit logs / Compliance API | Not published | Yes | OpenAI |
Compliance | SAML SSO | Yes | Yes | Tied |
Compliance | Default data deletion | 30 days | Varies by tier | Grok |
Reliability | Published uptime SLA | Not published | 99.9% (Scale Tier) | OpenAI |
Reliability | Service credits | Not documented | Yes (Scale Tier) | OpenAI |
Reliability | Committed throughput | Not documented | Yes (30-day min) | OpenAI |
Reliability | Enterprise latency SLAs | Not documented | Yes (Priority Tier) | OpenAI |
Vendor Risk | Annualized revenue | Not disclosed | $25B+ (Reuters, March 2026) | OpenAI |
Vendor Risk | Enterprise customer depth | Starlink (only named, May 2026) | Zillow, Deutsche Telekom, Priceline, Intercom, Glean, Foundation Health | OpenAI |
Vendor Risk | Federal government adoption | 3 named use cases | 234 named use cases (Reuters, May 2026) | OpenAI |
Vendor Risk | Governance risk | MechaHitler incident (July 2025); SpaceX SEC disclosures | Post-recapitalization complexity | OpenAI |
Category Score
Category | Winner |
Speech Reasoning | Grok |
Speed / Latency | Grok |
Conversational Dynamics (Overall) | OpenAI |
Interruption Handling | OpenAI |
Agentic Performance (Overall) | Grok |
Agentic Performance: Airline | OpenAI |
Agentic Performance: Retail | Grok |
Agentic Performance: Telecom | Grok |
Cost per Hour (vs High tier) | Grok |
Cost per Hour (vs Minimal tier) | Tied |
Voice Quality (TTS ELO) | N/A |
Pricing (per minute) | Grok |
Language Support | Grok |
Integration Ecosystem | OpenAI |
Agentic Tooling | OpenAI |
RAG / Knowledge Base | OpenAI |
Compliance | OpenAI |
Reliability / SLAs | OpenAI |
Vendor Risk | OpenAI |
Enterprise Customer Depth | OpenAI |
Grok wins: 9 categories. OpenAI wins: 10 categories. Tied: 1.
Grok wins the performance and economics categories. OpenAI wins the enterprise infrastructure and compliance categories. Which set of wins matters more depends entirely on what you're building and who you're building it for.
Tool Calling and Agentic Workflows
Both platforms can book appointments, look up orders, route calls, and update CRM records. The differences are architectural:
Capability | Grok Voice Think Fast 1.0 | OpenAI gpt-realtime-2 |
Background tool execution | Yes (core architecture) | No (preambles mask wait) |
Parallel tool calls | Not documented | Yes |
ComplexFuncBench score | Not published | 66.5% (original gpt-realtime baseline: 49.7%) |
Production tool count | 28 (Starlink deployment) | Not documented per customer |
Adjustable reasoning effort | Not documented | Yes (minimal → xhigh) |
Grok's background reasoning means 28 tools running across hundreds of workflows (Starlink's case) without dead air. OpenAI's parallel tool calls plus preambles achieve a similar UX result through different means.
Edge: Grok for tool-heavy phone workflows; OpenAI for complex multi-step reasoning with adjustable effort
Use-Case Fit
Choose Grok when:
You're running high-volume outbound/inbound sales, hospitality, telecom support, in-vehicle assistants, or cost-sensitive consumer support
You need 25+ language coverage in one model without a second translation layer
Your workflows are tool-heavy and background reasoning reduces your handle time
Your volumes exceed ~250K minutes/month and per-minute cost is the dominant line item
You want low-risk migration from OpenAI Realtime (same spec, base URL change)
Choose OpenAI when:
You're in healthcare, financial services, legal, education, or public sector
You need EU residency or signed BAAs as a prerequisite to launch
You require a documented uptime SLA with service credits
You're standardizing on a broader OpenAI stack (Codex, Responses API, Azure, Agents SDK)
Your brand cannot tolerate any association with prior Grok content incidents
Complex multi-turn reasoning with adjustable effort levels drives your use case
Pros and Cons at a Glance
Grok Voice Think Fast 1.0 | OpenAI gpt-realtime-2 | |
Voice Quality | Solid; vendor claims top pronunciation/prosody | Best-in-class instructability; Cedar/Marin voices |
Latency (TTFA) | 1.25s at high reasoning; architecture-level advantage | 2.33s; preambles mask the wait |
Benchmark Performance | Leads τ-Voice (52.1% vs 39.8%); 97.1% Big Bench Audio | Wins airline subdomain (63%); 96.6% Big Bench Audio |
Pricing | ~$0.05/min flat | ~$0.18 to $0.30/min |
Language Support | 25+ natively, mid-call switching | 9 conversational + 70+ via translate model |
API / Developer Experience | OpenAI-spec compatible; clean telephony integration | Deepest ecosystem; Azure · MCP · Agents SDK |
Tool Calling | Background reasoning; 28-tool production case | Parallel calls + preambles; ComplexFuncBench 66.5% |
RAG / Knowledge Base | Collections-based file_search | Managed vector stores (more mature) |
Compliance | SOC 2 · GDPR · HIPAA (case-by-case) | SOC 2 · ISO 27001/27701 · HIPAA · EU residency · zero-retention |
SLA / Uptime | Not published; negotiated directly | 99.9% (Scale Tier) with service credits |
Enterprise Customers | Starlink only (May 2026) | Zillow · Deutsche Telekom · Priceline · Intercom · Glean |
Vendor Risk | Brand risk from July 2025 incident; SpaceX governance | Governance complexity post-recapitalization |
Real-Time Agents | Purpose-built; background reasoning for tool-heavy flows | Agents SDK; preambles; adjustable reasoning effort |
How to Actually Choose
Answer one question first: is your business regulated, or does your deployment require a signed BAA or EU data residency before you can go live?
If yes, start with OpenAI. Don't benchmark first. Get the compliance paperwork in order, then run your evals.
If no, follow these steps:
Step 1: Model your real cost at projected volume. Don't use per-minute price as your unit. Calculate per-resolved-conversation cost. A model that costs twice as much per minute but resolves twice as many calls without escalation is the cheaper model by the metric that matters.
Step 2: Run a four-week head-to-head. Because Grok is OpenAI-spec compatible, you can run the same system prompt, the same tools, and the same call corpus against both APIs with a base URL change. That test tells you more than any benchmark.
Step 3: Set three decision gates, not one. Track task completion rate on 100 to 200 representative calls, average handle time, and per-resolved-conversation cost. If Grok wins all three and your legal team is comfortable, Grok wins.
Step 4: Architect for hybrid from day one. Most production voice deployments end up multi-model: a fast, cheaper model for triage and outbound, a more capable model for complex cases, a translation model for multilingual segments, and a streaming transcription model for compliance. Build for swapability now. It costs less to do it at the start.
Trigger points to revisit your decision:
Move to OpenAI if: you sign a regulated-industry contract requiring a BAA or EU residency; your call mix shifts toward complex multi-turn reasoning; or OpenAI publishes a price cut closing the cost gap.
Move to Grok if: your voice volumes exceed ~250K minutes/month and model cost becomes the dominant line item; Grok-on-AWS-GovCloud or Grok-on-Azure becomes available; or independent benchmarks continue to show Grok widening the latency lead.
What the Production Numbers Say
Starlink's deployment of grok-voice-think-fast-1.0 is the only publicly verified enterprise case study for Grok as of May 2026. Their reported numbers: 70% autonomous resolution and 20% inbound-sales conversion across 28 tools. Vendor-derived. Not independently audited. Useful directional signal.
On the OpenAI side: Zillow reported a 26-point lift in call success rate; Glean reported 42.9% helpfulness improvement; Genspark reported a 26% conversation rate improvement. Also vendor-derived. Also useful directional signals. Also not your business.
The only numbers that matter for your decision are the ones you measure on your own call corpus, with your own tools, against your own definition of "resolved."
The teams shipping working voice agents in 2026 are not the ones with the highest benchmark scores. They're the ones who've already debugged barge-in deadlocks, tuned VAD for noisy telephony environments, and built eval pipelines against real call recordings.
Frequently Asked Questions
Is Grok Voice ready for enterprise production in 2026?
Does Grok Voice support HIPAA compliance?
Can I switch from OpenAI Realtime to Grok Voice without rewriting everything?
Which platform is better for multilingual customer support?
What's the biggest risk people overlook when choosing a voice AI platform?
The Bottom Line
OpenAI gpt-realtime-2 is the defensible default for most enterprise buyers in 2026, especially if you're in a regulated industry or standardizing on the broader OpenAI ecosystem. The compliance posture is more mature, the SLAs are documented, and the enterprise customer roster is wider.
Grok Voice Think Fast 1.0 is the serious contender when unit economics drive the business case. At high call volumes, the cost difference compounds in ways that matter. The latency advantage is real. The background reasoning architecture is genuinely well-suited to tool-heavy phone workflows.
The gap is narrowing on both sides. Grok's enterprise customer roster will grow; OpenAI has continued financial incentive to price more aggressively. But right now, they're genuinely different products built for different outcomes.
Neither platform wins on model quality alone. Both are good enough. The question is which fits your risk profile, your regulatory environment, and your cost structure.
Pick that one. Build the eval harness. Measure what actually matters.

References
OpenAI. "Realtime API General Availability Announcement." August 28, 2025. https://openai.com/blog
OpenAI. "gpt-realtime-2 Launch." May 7, 2026. https://openai.com/blog
OpenAI. Pricing page. https://openai.com/pricing (accessed May 2026)
OpenAI. Security practices page. https://openai.com/security (accessed May 2026)
xAI. "grok-voice-think-fast-1.0 Launch." April 23, 2026. https://x.ai/news
xAI. Pricing page. https://x.ai/api (accessed May 2026)
xAI. Security page. https://x.ai/security (accessed May 2026)
Artificial Analysis. Independent τ-Voice benchmark results, May 2026. https://artificialanalysis.ai
Artificial Analysis. Big Bench Audio results, May 2026. https://artificialanalysis.ai
The Batch / DeepLearning.AI. Coverage of Grok Voice latency benchmarks, April 2026. https://deeplearning.ai/the-batch
Reuters. "OpenAI Tops $25 Billion in Annualized Revenue." March 4, 2026. https://reuters.com
Reuters. "Federal AI Inventory Review: 400+ Government AI Use Cases." May 21, 2026. https://reuters.com
NPR. Coverage of the MechaHitler incident. July 8, 2025. https://npr.org
Anti-Defamation League. Statement on Grok content. July 2025. https://adl.org
Twilio. Published SIP trunking rates. https://twilio.com/en-us/voice/pricing (accessed May 2026)


